Stable Diffusion是stability.ai开源的图像生成模型。Stable Diffusion能够从文本描述中生成详细的图像,它还可以用于图像修复、图像绘制、文本到图像和图像到图像等任务。
标签:AI文生图模型 ComfyUI Stable Diffusion Stable Diffusion WebUI Stable Diffusion WebUI Forge WebUI 文生图模型


Stable Diffusion是什么?
Stable Diffusion是stability.ai开源的图像生成模型,是一种在潜在空间扩散(latent diffusion)的模型。它不是在高维图像空间中操作,而是首先将图像压缩到潜空间(latent space)中。然后,通过在潜空间中应用扩散过程来生成新的图像。
Stable Diffusion能够从文本描述中生成详细的图像,它还可以用于图像修复、图像绘制、文本到图像和图像到图像等任务。简单地说,我们只要给出想要的图片的文字描述,Stable Diffusion就能生成符合你要求的逼真的图像!可以说Stable Diffusion的发布将AI图像生成提高到了全新高度,其效果和影响不亚于Open AI发布的ChatGPT。
Stable Diffusion的核心概念
Stable Diffusion的核心概念包括:自动编码器、U-Net、文本编码器等。
1、自动编码器
自动编码器(VAE)由两个主要部分组成:编码器和解码器。编码器将图像转换为低维潜在表示,该表示将作为输入传递给 U_Net。解码器则相反,它将潜在表示转换回图像。
2、U-Net
U-Net是一种全卷积网络,用于语义分割,它由两个分支组成:编码器和解码器。编码器将输入图像分成大小相等的补丁,然后将这些补丁传递到下一级处理,解码器将这些补丁重新组合成输出图像。U-Net的优点是它可以在不同的尺度上进行预测,并且可以使用较少的训练数据来训练模型 。
3、文本编码器
文本编码器会将输入提示转换为 U-Net 可以理解的嵌入空间,一般是一个简单的基于Transformer的编码器,它将标记序列映射到潜在文本嵌入序列。
Stable Diffusion 是强大的开源AI绘画模型,只需要输入一句提示词(prompt),就能够在几秒钟内创造出令人惊叹的绘画作品。
Stable Diffusion 完全免费开源,所有代码均在 GitHub 上公开,任何人都可以拷贝使用。
官网:https://stability.ai/
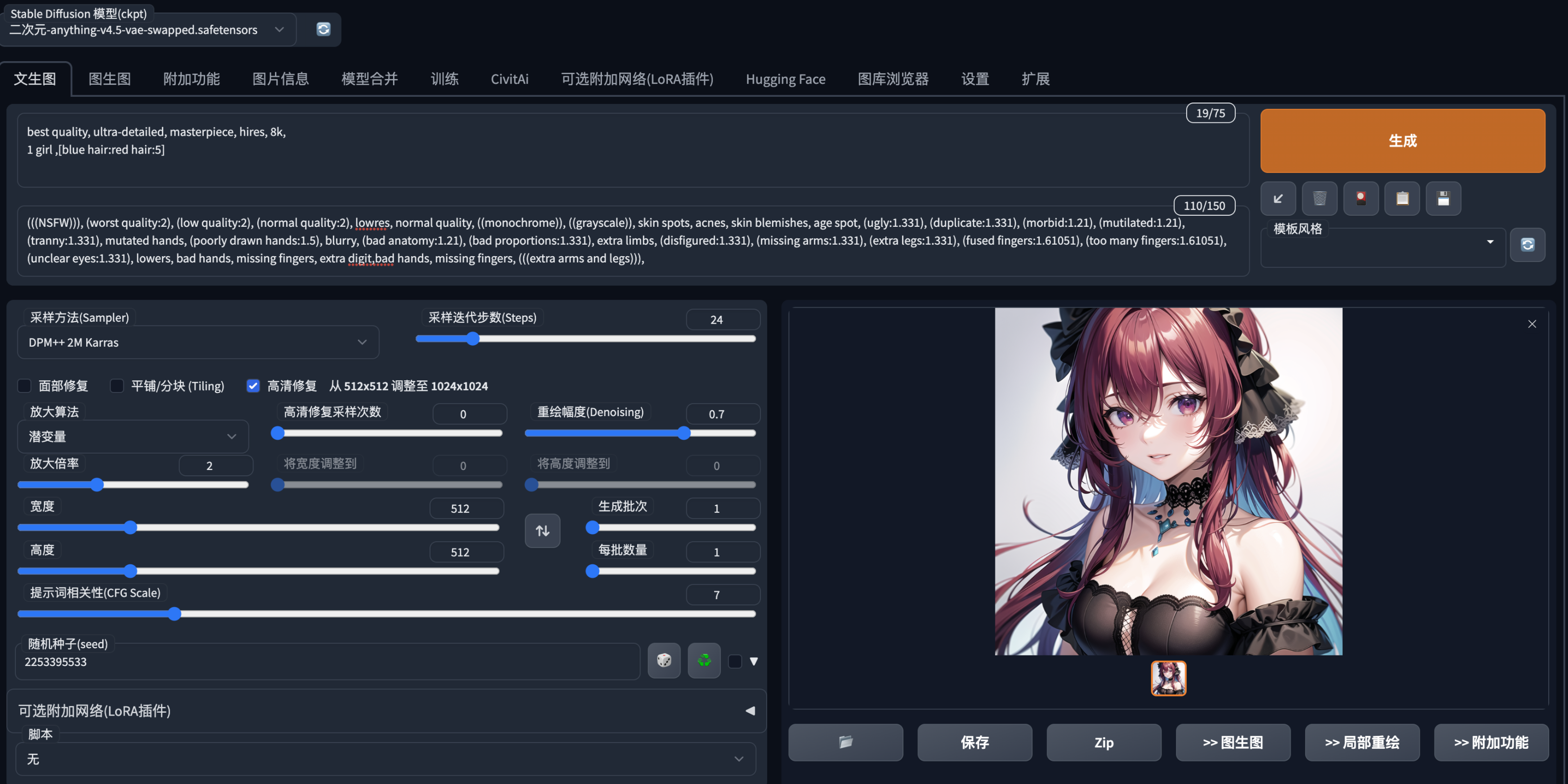
如何使用Stable Diffusion?
1、本地部署Stable Diffusion
(1)、Stable-Diffusion-WebUI:https://github.com/AUTOMATIC1111/stable-diffusion-webui
整合包下载地址:
(2)、Stable Diffusion WebUI Forge:https://github.com/lllyasviel/stable-diffusion-webui-forge
整合包下载地址:
(3)、ComfyUI:https://github.com/comfyanonymous/ComfyUI
2、Photoshop插件
https://exchange.adobe.com/apps/cc/114117da/stable-diffusion
3、开发者API调用
https://platform.stability.ai/
4、GitHub开源地址
https://github.com/Stability-AI/stablediffusion
5、Hugging face地址
https://huggingface.co/stabilityai/stable-diffusion-2-1
Stable Diffusion Reimagine介绍和使用
https://www.aihub.cn/tools/image/stable-diffusion-reimagine/
Stable Diffusion使用教程
【秋叶大神】从零开始的AI绘画入门教程:https://www.bilibili.com/read/cv22159609