













什么是LaVie
LaVie是由上海人工智能实验室联合多所知名大学共同研发的成果。它不仅是一个技术框架,更是一个创意的引擎,能够根据文本描述生成视觉真实、时间连贯的视频内容。
这一技术的实现,得益于预训练的文本到图像模型作为基础,结合了先进的视频生成算法和大规模的高质量视频数据集Vimeo25M。
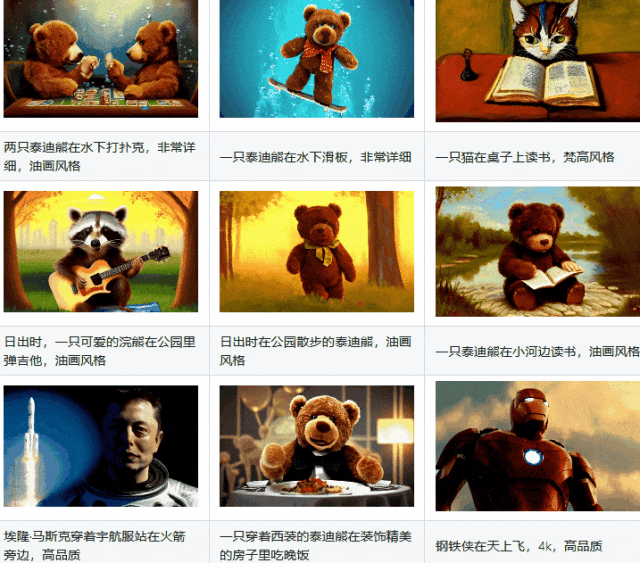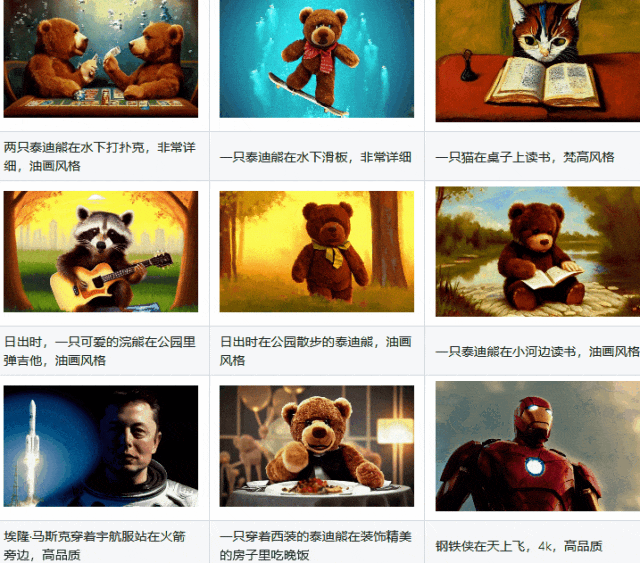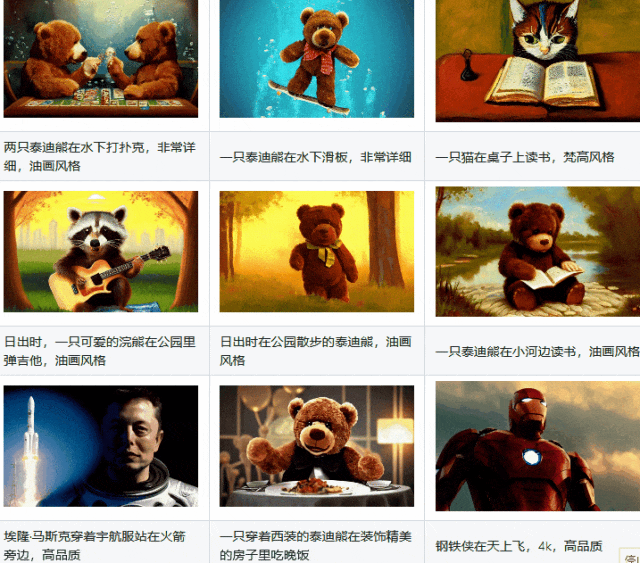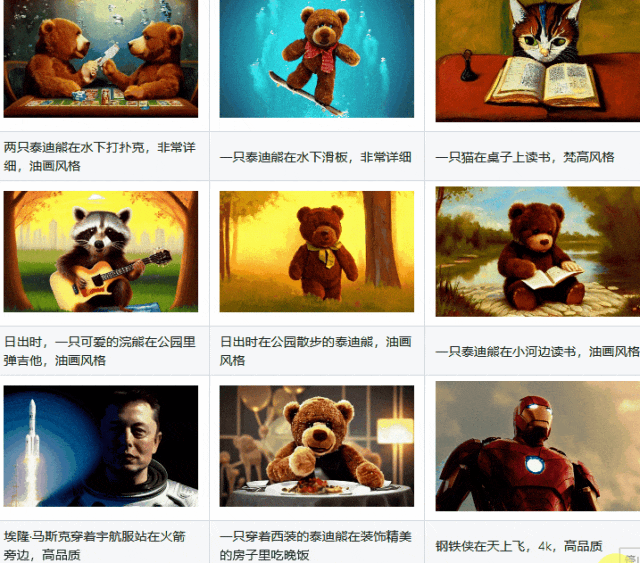
LaVie相关链接
LaVie项目链接:https://github.com/Vchitect/LaVie
LaVie功能特点
LaVie的技术核心,级联潜在扩散模型(Cascaded Latent Diffusion Models),是一种创新的深度学习架构,它将视频生成任务分解为三个阶段:基础文本到视频(Base T2V)、时间插值(Temporal Interpolation),以及视频超分辨率(Video Super-Resolution)。
这一级联方法不仅提高了视频生成的质量和效率,还增强了结果的可控制性和可定制性。
1.基础T2V模型:作为级联的起点,它负责生成与文本描述基本对应的低分辨率关键帧。这些帧是视频的“骨架”,捕捉了文本中描述的主要元素和动作。
2.时间插值模型:在基础帧的基础上,时间插值模型通过扩散UNet技术,将帧率提升,生成更加流畅的视频。这一步骤不依赖简单的帧复制或插值,而是重新合成每一帧,确保视频在时间上的连贯性和细节的丰富性。
3.视频超分辨率模型:最后,超分辨率模型进一步提升视频的清晰度,将视频分辨率提升至2K标准。这一模型利用3D卷积和时间注意力层,增强了视频的空间分辨率和时间上的连贯性。
LaVie的创新之处在于其简洁而高效的设计原则,这在级联模型的每个阶段都得到了体现:
1.时间自注意力机制:LaVie采用了简化版的时间自注意力模块,这种设计既保留了自注意力机制捕捉长距离依赖的能力,又避免了过度复杂的计算,使得模型更加高效。
2.旋转位置编码(RoPE):LaVie引入了旋转位置编码来进一步增强模型对视频时间维度的理解。RoPE是一种新颖的编码方式,能够有效地将时间信息融入到模型中,提升了视频生成的准确性和表现力。
3.联合图像-视频微调:LaVie的另一个创新点在于其训练策略。通过在图像和视频数据集上进行联合微调,模型不仅学习到了图像的丰富视觉特征,还获得了视频的时间动态特性,这大大提升了生成视频的质量和多样性。
4.高效的知识转移:LaVie通过从大规模预训练的文本到图像模型中转移知识,加速了学习过程,并提高了视频生成的创意性和视觉真实性。这种策略避免了从头开始训练整个视频生成系统所需的巨大计算资源。
LaVie应用场景
LaVie的应用场景极为广泛。无论是电影制作、游戏设计还是艺术创作,LaVie都能够根据文本描述快速生成所需的视频内容。此外,LaVie在长视频生成和个性化视频合成方面也展现出了巨大的潜力。




