













什么是AnyDoor
AnyDoor是香港大学、阿里集团、蚂蚁集团联合开源了基于扩散模型的,图像生成、控制模型。AnyDoor实现了零样本的图像嵌入,主要功能是“图像传送”,点两下鼠标,就能把物体无缝「传送」到照片场景中,光线角度和透视也能自动适应。例如,将女生的蓝色短袖换成其他样式的红色衣服。所以。有了它,网购衣服也可以直接看上身效果了。

AnyDoor相关链接
开源地址:https://github.com/ali-vilab/AnyDoor
论文地址:https://arxiv.org/abs/2307.09481
Demo地址:https://huggingface.co/spaces/xichenhku/AnyDoor-online
AnyDoor摘要
这个作品展示了AnyDoor,一个有能力将目标物体以和谐的方式传送到用户指定的位置的新的场景,我们的模型只训练一次,而不是为每个对象调优参数,在推理阶段轻松地推广到不同的对象场景组合。这样具有挑战性的零样本设置需要对某个对象进行充分的表征。为此,我们用细节特征补充了常用的身份特征,这些细节特征经过精心设计,以保持纹理细节,但允许灵活的局部变化(例如,照明、方向、姿势等),支持对象与不同的环境良好地融合。我们进一步建议从视频数据集借鉴知识,在那里我们可以观察到单个对象的各种形式(即沿着时间轴),从而导致更强的模型泛化性和鲁棒性。广泛的实验表明,我们的方法优于现有的替代方法,并在现实世界的应用中具有巨大的潜力,例如虚拟试穿和物体移动。
AnyDoor工作原理
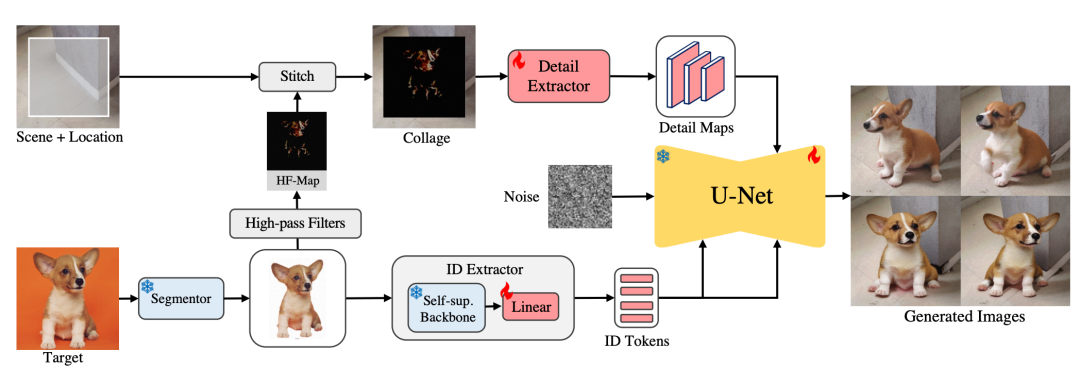
AnyDoor目的是将对象传送到用户指定位置的场景。首先采用分割模块从对象中删除背景,然后使用ID提取器获取其身份信息。然后,我们对“干净”的对象应用高通滤波器,将所得的高频图(HF-Map)与期望位置的场景拼接起来,并使用细节提取器以纹理细节补充ID提取器。最后,将ID标记和细节图注入预训练的扩散模型,以产生最终的合成,其中目标对象与其周围环境良好地融合,但具有良好的局部变化。火焰和雪花分别指可学习和冻结的参数。
要想实现物体的传送,首先就要对其进行提取。不过在将包含目标物体的图像送入提取器之前,AnyDoor首先会对其进行背景消除。然后,AnyDoor会进行自监督式的物体提取并转换成token。这一步使用的编码器是以目前最好的自监督模型DINO-V2为基础设计的。为了适应角度和光线的变化,除了提取物品的整体特征,还需要额外提取细节信息。这一步中,为了避免过度约束还设计了一种用高频图表示特征信息的方式。

ID提取器是一种专注于焦点区域的视觉细节提取器。"Attention"指的是用于该ID(DINO-V2)的注意力图提取器的骨干部分,而"HF-Map"则指用于细节提取器中使用的高频率图。这两个模块侧重于互补的全局和局部信息。
最后一步就是将这些信息进行注入。利用获取到的token,AnyDoor通过文生图模型对图像进行合成。具体来说,AnyDoor使用的是带有ControlNet的Stable Diffusion。以上就是AnyDoor的工作大致流程。
AnyDoor产品总结
AnyDoor模型主要用于一键换脸/换衣、虚拟试穿、在线PS等业务场景。可以让很多不懂技术的电商卖家,也能实现专业PS的功能。但目前效果还略微粗糙,需要继续精雕细琢。另外交互对用户来说还不是特别方便,相信AnyDoor一定也会进一步的优化。





