LEGO是一个由字节跳动和复旦大学联合研发的多模态理解和图像定位模型。这一模型具有处理和理解多种类型的输入的能力,包括图像、音频和视频。同时,LEGO还具备精准定位的能力,能够在图像中标识出物体的具体位置,在视频中指出特定事件发生的时间点,在音频中识别出特定声音的来源。
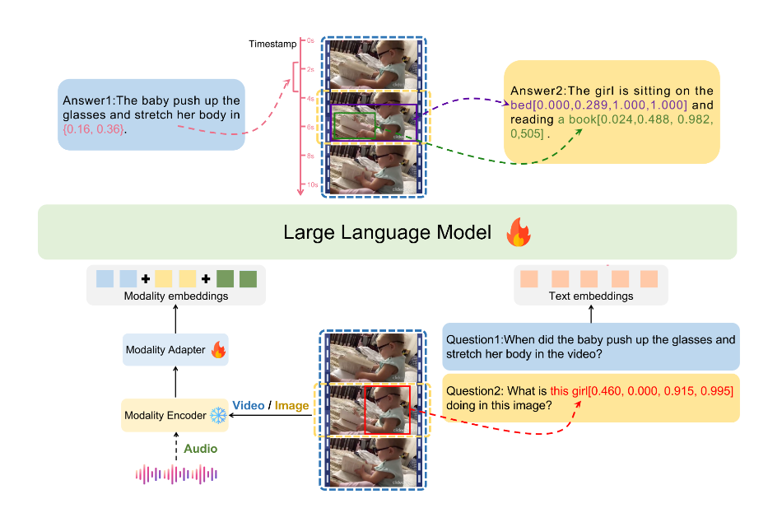
该模型的主要功能特点包括多模态理解、强大的定位能力、构建高质量数据集、应对复杂任务、广泛的应用潜力以及实时处理和响应。LEGO模型可以处理包含多个元素和复杂指令的任务,根据详细的描述或指令来分析和解释内容,提供准确的输出。
项目地址:https://lzw-lzw.github.io/LEGO.github.io/
由于其多模态理解和定位的能力,LEGO模型适用于广泛的应用场景,包括内容创作、教育、娱乐、安全监控等领域。此外,LEGO模型还能够快速处理输入并生成响应,适用于需要实时分析和反馈的应用场景。
LEGO项目的工作原理包括对多种模态数据的处理、特征提取、融合和上下文分析,最终根据用户的需求生成精确的定位和响应。模型首先处理多种类型的输入数据,包括图像、音频和视频,并进行解析和预处理以适合进一步的分析。
然后,模型提取每种输入数据的关键特征,并将这些特征进行融合,形成一个统一的、多层次的理解。接下来,模型分析整合后的数据以及相应的上下文信息,最终根据用户的指令或查询进行定位和响应,并生成相应的输出结果。
LEGO模型的研发和应用将为多模态理解和图像定位领域带来重大的突破,为相关领域的发展提供新的思路和解决方案。
来源:站长之家
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!