Vision Transformer(ViT)是一种基于Transformer架构的深度学习模型,最初由Google Research在2020年提出,用于图像识别任务。ViT的核心思想是将图像分割成固定大小的小块(patches),这些小块被线性嵌入到向量中,并添加位置编码以保留图像的空间信息。这些向量随后被输入到Transformer编码器中,通过多头自注意力机制捕捉图像中的全局特征和长距离依赖关系。
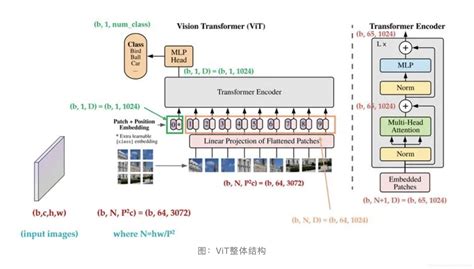
ViT的主要优势在于其不依赖卷积操作,而是直接利用Transformer的自注意力机制来处理图像数据,这使得它在处理大规模图像数据时表现出色,并且在某些任务上甚至超越了传统的卷积神经网络(CNN)。此外,ViT还具有灵活性、可扩展性和可解释性等特性,使其在计算机视觉领域具有广泛的应用潜力。
ViT不仅适用于图像分类任务,还可以扩展到目标检测、语义分割等其他计算机视觉任务中。然而,ViT也面临一些挑战,如计算成本高、对大量数据的需求以及在小数据集上的过拟合问题。尽管如此,ViT的出现为计算机视觉领域带来了新的研究方向和应用前景
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!