TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种用于文本挖掘和信息检索的统计分析方法,旨在评估一个词语在文档或语料库中的重要性。其核心思想是结合词语在单篇文档中的出现频率(TF)和该词语在整个语料库中的稀有程度(IDF),从而更准确地衡量词语的重要性。
TF-IDF的组成部分:
- TF(词频) :表示某个词在文档中出现的频率。通常用该词在文档中出现的次数除以文档中的总词数来计算。例如,如果一个词在文档中出现了5次,而文档总共有100个词,那么它的TF值为0.05。
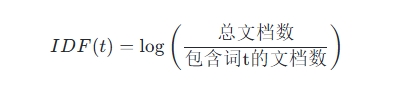
- IDF(逆文档频率) :衡量某个词在整个语料库中的稀有程度。IDF值越高,表示该词在语料库中出现的文档越少,因此其区分能力越强。IDF的计算公式为:
IDF(t)=log(总文档数包含词t的文档数)
其中,总文档数是语料库中所有文档的数量,包含词t的文档数是包含该词的所有文档的数量。
TF-IDF的计算公式:
TF-IDF值是TF和IDF的乘积,即:
其中,t 表示词语,d 表示文档,D 表示整个语料库。
TF-IDF的应用:
- 信息检索:TF-IDF常被用于搜索引擎中,作为文件与用户查询之间相关程度的度量或评级。例如,通过计算查询词在网页中的TF-IDF值,可以确定网页与查询的相关性。
- 文本分类:在文本分类任务中,TF-IDF用于提取特征词权重,帮助模型区分不同类别的文本。例如,通过计算每个类别中词语的TF-IDF值,可以识别出最具代表性的特征词。
- 关键词提取:TF-IDF也被用于从文本中提取关键词或短语,帮助总结文档内容或识别主题。
优点与局限性:
- 优点:简单快速,结果符合实际情况,能够有效过滤掉常见但不重要的词语。
- 局限性:高维稀疏性、无法考虑词语的位置因素、忽略特征词在类间分布情况等。
改进方法:
为了克服传统TF-IDF的不足,研究者提出了多种改进方法,例如结合词项语义信息、引入新词权重、考虑词语上下文环境等。
TF-IDF是一种重要的文本特征提取技术,在信息检索、文本分类和关键词提取等领域有着广泛的应用。然而,在实际应用中需要根据具体需求选择合适的改进方法以提高效果。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!