Kappa系数是一种用于衡量分类模型或评估者之间一致性的统计指标,其值范围介于-1到1之间。Kappa系数通过比较实际一致率与偶然一致率之间的差异来评估分类结果的一致性程度。
具体来说,Kappa系数的计算公式为:

- Po(Observed Agreement):
Po表示观察到的一致性,即两个评判者在分类时实际达成一致的比例。例如,如果两个评判者都正确地将某个样本分类为某一类别,则这一分类结果被计入Po中。Po的值范围从0到1,值越大表示一致性越高。例如,如果两个评判者在所有情况下都完全一致,则Po=1;如果完全不一致,则Po=0。 - Pe(Expected Agreement):
Pe表示偶然一致性,即如果两个评判者完全独立地随机选择分类结果,那么他们达成一致的概率。Pe考虑了评判者各自独立选择每个类别的概率,从而计算出他们偶然达成一致的可能性。Pe的值同样在0到1之间,值越大表示偶然一致性越高。例如,如果评判者随机选择分类结果,那么Pe=1;如果评判者总是选择不同的类别,则Pe=0。
通过比较Po和Pe,Kappa系数能够衡量评判者之间的一致性是否超出偶然水平。
Kappa系数的解释如下:
- 当 κ=1 时,表示完全一致,即分类结果与实际标签完全吻合。
- 当 κ=0时,表示分类结果与随机一致,即分类结果与实际标签没有显著相关性。
- 当 κ<0 时,表示一致性比随机一致还要差,可能是因为分类器的表现非常糟糕。
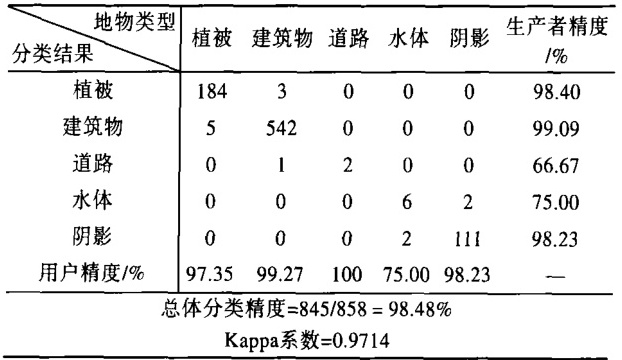
在实际应用中,Kappa系数常用于机器学习、遥感影像分类、医学诊断等领域,用来评估分类模型的性能或多个评估者之间的判断一致性。例如,在遥感影像分类中,Kappa系数可以用来衡量分类精度,从而判断分类结果是否可靠。
Kappa系数是一种重要的统计工具,用于量化分类结果的一致性,并帮助研究者评估模型或评估者的性能。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!