什么是IDF(逆文档频率)
逆文档频率(Inverse Document Frequency,IDF)是信息检索和自然语言处理领域中用于衡量一个词语在整个文档集合中的重要性的统计指标。IDF 的核心思想是:如果一个词在少数文档中出现,那么这个词具有较高的区分能力,因此其IDF值较高;反之,如果一个词在大多数文档中频繁出现,则其区分能力较弱,IDF值较低。
IDF 的计算公式
IDF 的计算公式通常表示为:
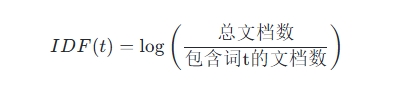
这个公式通过对数函数将IDF值压缩到一个较小的范围内,可通过加1确保IDF值始终为正。
IDF 的作用
- 区分度:IDF 能够帮助识别那些在少数文档中出现的“特殊”词,这些词有助于区分不同文档。例如,在文本分类任务中,IDF可以帮助模型识别出能够有效区分不同类别的关键词。
- 信息量:IDF 衡量了词语在整个文档集合中的普遍性。一个词如果在所有文档中都频繁出现,则其信息量较低;而如果仅在少数文档中出现,则其信息量较高。
- 优化搜索结果:在信息检索中,IDF 被用于计算TF-IDF权重,以提高搜索结果的相关性和准确性。TF-IDF 是词频(TF)和逆文档频率(IDF)的乘积,能够综合反映词语在特定文档中的重要性。
实际应用
- 文本分类:通过计算词语的IDF值,可以筛选出具有高区分能力的关键词,从而提高文本分类的准确性。
- 信息检索:IDF 被广泛应用于搜索引擎中,用于评估查询词与文档的匹配度,从而优化搜索结果。
- 推荐系统:在推荐系统中,IDF 可以帮助理解用户兴趣与内容之间的关联,提供更个性化的推荐。
总结
逆文档频率(IDF)是一种重要的统计技术,用于衡量词语在文档集合中的重要性。它通过计算词语在所有文档中的分布情况来评估其信息量和区分能力,从而在信息检索、文本分类和自然语言处理等领域发挥重要作用
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!