DINO(Distillation in Self-Supervised Vision Transformers)是一种由Facebook AI Research(FAIR)开发的自监督学习框架,主要用于计算机视觉任务。其核心思想是通过教师-学生架构和知识蒸馏技术,使模型能够从无标签数据中学习到丰富的视觉特征表示。
DINO的基本原理
- 教师-学生架构:DINO采用了一个教师网络和一个学生网络的双模型结构。教师网络负责生成全局视图(Global View),而学生网络则接收多个局部视图(Local Views)。这种设计使得学生网络能够学习到全局和局部的特征表示。
- 知识蒸馏:通过对比损失函数(Contrastive Loss)和交叉熵损失函数,DINO将教师网络的输出传递给学生网络,从而引导学生网络学习到更优的特征表示。教师网络的参数通过动量更新机制逐渐接近学生网络的参数。
- 多裁剪策略:DINO在训练过程中使用多种裁剪策略,包括全局裁剪和局部裁剪,以获取图像的不同视图。这些视图帮助学生网络更好地捕捉图像的多样性和复杂性。
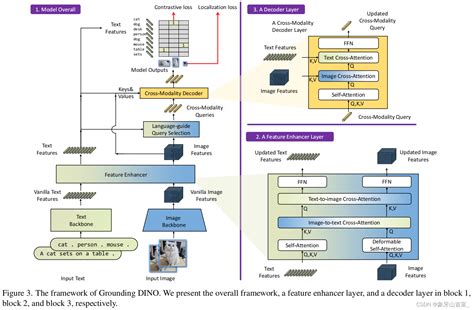 Grounding DINO: Marrying DINO with Grounded Pre-Training forOpen-Set ...
Grounding DINO: Marrying DINO with Grounded Pre-Training forOpen-Set ...
DINO的应用领域
- 图像分割:DINO能够自动分割图像中的对象,无需人工标注。它通过生成注意力图来突出图像中的关键前景对象,从而实现高精度的图像分割。
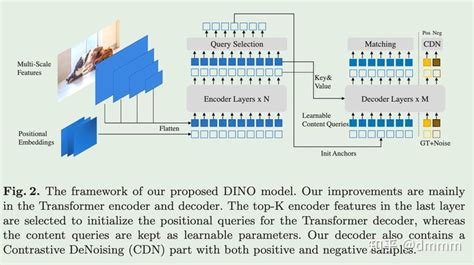
 Enhanced Zero-shot Labeling through the Fusion of DINO and Grounded Pre ...
Enhanced Zero-shot Labeling through the Fusion of DINO and Grounded Pre ... - 目标检测:DINO在目标检测任务中表现出色,尤其是在开放集检测(Open-Set Detection)中。通过结合文本提示和图像特征,DINO能够根据文本描述检测和定位特定目标。
 「目标检测简述」DINO - 知乎
「目标检测简述」DINO - 知乎 - 语义分割:DINO在语义分割任务中也展现了强大的能力,能够从图像中提取丰富的语义信息,并用于后续的分类和分割任务。
- 生物医学成像:DINO在单细胞形态学分析和蛋白质定位预测等生物医学领域也表现出色。它能够从显微镜图像中学习细胞形态的异质性,并用于分类和预测。
DINO的优势
- 无需标注数据:DINO通过自监督学习,能够在没有标注数据的情况下训练模型,大大减少了对人工标注数据的依赖。
- 泛化能力强:DINO通过多裁剪策略和知识蒸馏技术,能够学习到更具泛化性的特征表示,适用于多种计算机视觉任务。
- 高效性:DINO的训练过程不需要大量的计算资源,且收敛速度快,适合大规模数据集的训练。
DINO的改进版本
- DINOv2:作为DINO的升级版本,DINOv2进一步优化了训练流程和数据管道,提高了模型性能。它使用了更大的数据集(如LVD-142M)和更高质量的特征表示。
- Grounding DINO:结合了文本和图像信息的Grounding DINO,能够在开放集检测任务中根据文本提示检测和定位目标。它通过双编码器-单解码器架构实现了文本与图像之间的无缝连接。
总结
DINO是一种基于自监督学习的视觉变换器模型,通过教师-学生架构和知识蒸馏技术,能够在无标签数据上学习到丰富的视觉特征表示。它在图像分割、目标检测、语义分割等多个计算机视觉任务中表现出色,并在生物医学成像等领域展现了广泛的应用潜力。随着其改进版本(如DINOv2和Grounding DINO)的推出,DINO在实际应用中的表现将进一步提升。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!