CLIP文本编码器(CLIP Text Encoder)是CLIP(Contrastive Language-Image Pre-training)模型中的关键组件之一,其主要功能是将输入的自然语言文本转换为嵌入向量,从而实现对文本语义的数字化表示。这一过程为后续的任务(如图像生成、匹配、分类等)提供了基础支持。
1. CLIP文本编码器的基本结构
CLIP文本编码器基于Transformer架构,通过自注意力机制和多层感知器(MLP)来处理文本数据。具体来说,它将输入的文本序列(如句子或短语)编码为一个高维向量,该向量表示了文本的整体语义信息。例如,在一些实现中,它会输出一个长度为512的向量,用于表示输入文本的语义特征。
2. 工作原理
CLIP文本编码器的工作流程如下:
- 输入:接收一个字符串形式的文本提示(Prompt),例如“一个男孩站在户外”。
- 处理:利用Transformer模型逐词处理文本,提取每个词的嵌入表示,并通过自注意力机制整合上下文信息。
- 输出:生成一个固定长度的向量(通常是512维),用于后续任务的条件输入或对比学习。
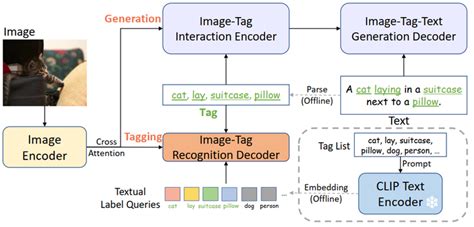
3. 应用场景
CLIP文本编码器被广泛应用于多种任务中,包括但不限于:
- 图像生成:通过将文本提示编码为向量,指导扩散模型生成符合文本描述的图像。
- 图像匹配与分类:将文本和图像嵌入映射到同一空间中,用于计算它们之间的相似性。
- 零样本学习:在完全冻结参数的情况下,仅通过文本提示即可完成分类任务。
- 跨模态检索:结合图像编码器,从图像库中检索与文本描述最匹配的图像。
4. 技术特点
- 对比学习:CLIP通过对比损失函数将文本和图像嵌入对齐到同一潜在空间,从而实现跨模态理解。
- 预训练与微调:CLIP模型通常在大规模的图像-文本对数据集上进行预训练,然后可以根据特定任务进行微调。
- 灵活性:支持动态和多行文本输入,适用于复杂的提示生成。
5. 实现细节
在实现上,CLIP文本编码器通常包含以下模块:
6. 优势与局限
- 优势:
- 能够捕捉复杂的语义信息,支持零样本学习。
- 在跨模态任务中表现出色,如图像生成和分类。
- 局限:
- 对于非常长的文本提示可能表现不佳。
- 需要大量计算资源进行训练和推理。
CLIP文本编码器是一种强大的工具,能够将自然语言文本高效地转化为数字表示,为多模态任务提供支持。其基于Transformer架构的设计使其在多种应用场景中具有广泛适用性,并且通过对比学习实现了跨模态的深度理解。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!