AMP(自动混合精度)是一种在深度学习模型训练中通过结合单精度(FP32)和半精度(FP16)数据类型来提高训练效率的技术。其核心目标是在保持模型精度的同时,减少内存占用、提升计算效率,并加快训练速度。
AMP混合精度训练的原理
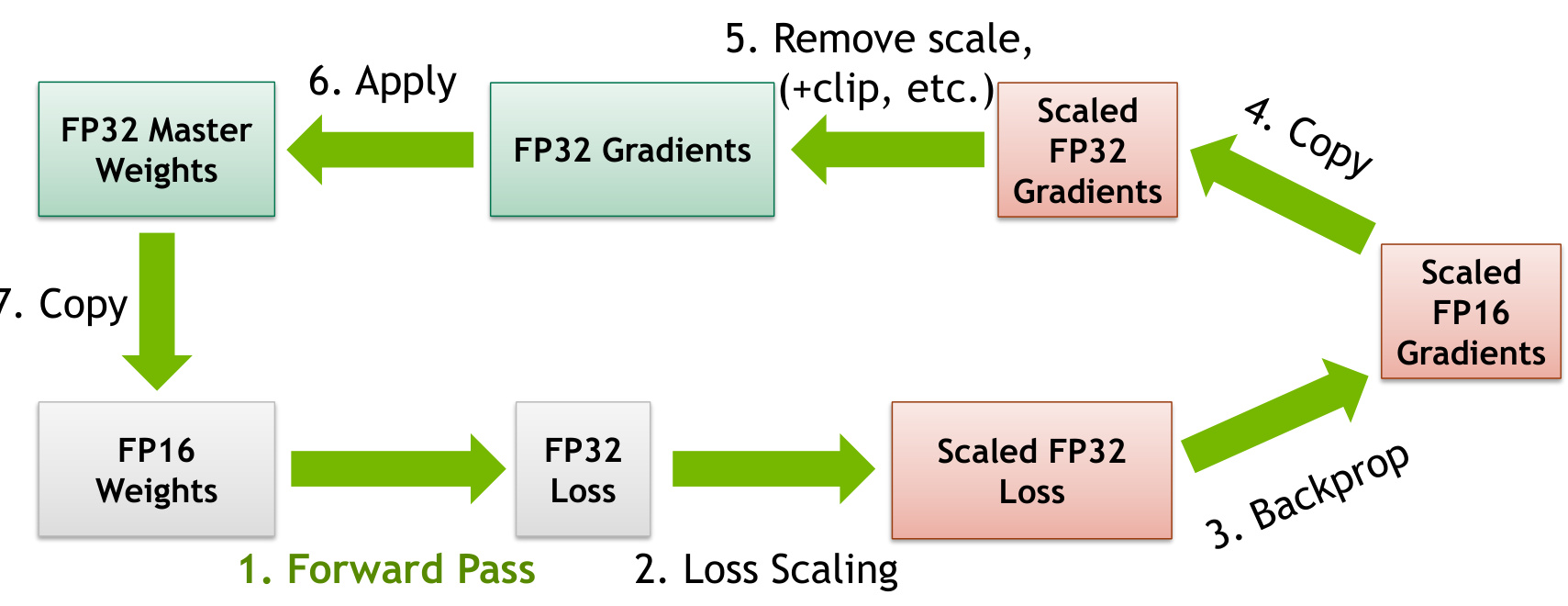
AMP技术通过动态地在FP32和FP16之间切换,利用FP16的存储和计算优势来加速训练过程,同时通过梯度缩放机制确保数值稳定性。具体来说:
- 数据类型切换:在训练过程中,模型的某些操作(如矩阵乘法)使用FP16进行计算,而其他需要更高精度的操作(如损失函数计算)则使用FP32。这种“混合”精度策略既节省了显存,又避免了FP16带来的舍入误差问题。
- 梯度缩放:由于FP16的数值范围较小,可能导致梯度消失或爆炸。为此,AMP引入了动态损失缩放(Dynamic Loss Scaling)机制,通过放大损失值来防止梯度消失,并在反向传播后缩放梯度以恢复其正常值。
- 自动转换:PyTorch中的
torch.cuda.amp模块提供了amp.autocast()上下文管理器,自动将张量从FP32转换为FP16,并在需要时回退到FP32,从而简化了代码实现。
AMP的优势
- 内存与计算效率:使用FP16代替FP32可以减少一半的存储空间和内存带宽需求,同时提升计算吞吐量。例如,在GPU上,FP16内核的计算吞吐量是FP32的8倍。
- 加速训练:AMP可以显著缩短训练时间,通常可提升50%-60%的训练速度。
- 兼容性与易用性:PyTorch从1.6版本起内置了AMP功能,用户只需添加少量代码即可启用,无需额外安装第三方库。
- 灵活性:AMP支持多种精度模式(如FP16、BF16等),并允许用户根据需求调整缩放策略。
AMP的应用场景
AMP广泛应用于需要大规模计算和高效率的场景,例如:
- 深度学习模型训练:在图像分类、自然语言处理等领域,AMP显著提升了训练速度和资源利用率。
- 分布式训练:在多卡或多节点环境中,AMP结合分布式数据并行(DDP)技术进一步优化了训练性能。
- AI芯片优化:AMP技术也被应用于AI加速芯片中,通过动态调整精度操作来提升推理和训练效率。
AMP的实现细节
在PyTorch中,AMP的实现依赖于以下关键组件:
torch.cuda.amp.GradScaler:用于动态调整损失缩放因子,防止梯度消失或爆炸。torch.cuda.amp.autocast():自动将张量转换为FP16或回退到FP32。
- 梯度更新:在反向传播时,通过缩放梯度来保持数值稳定性,并在权重更新时恢复原始值。
注意事项
尽管AMP带来了显著的性能提升,但在实际应用中需要注意以下几点:
- 数值稳定性:虽然梯度缩放机制可以缓解数值问题,但某些情况下仍可能出现溢出或下溢,需谨慎调试。
- 硬件支持:AMP的效果依赖于GPU的支持,如Tensor Core架构可显著提升FP16运算性能。
- 模型适用性:并非所有模型都适合AMP,某些依赖高精度运算的层(如softmax)可能需要保留为FP32。
AMP混合精度训练是一种高效且易于实现的技术,通过结合FP32和FP16的优势,在保持模型精度的同时显著提升了训练效率。它已成为现代深度学习框架的重要工具之一,并在多个领域得到了广泛应用。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!