自适应学习率算法是一种在优化过程中动态调整学习率的方法,旨在根据当前参数值、梯度信息或其他统计量来优化学习率,从而提高模型训练的效率和收敛速度。与传统的固定学习率方法相比,自适应学习率算法能够更好地应对梯度变化的不稳定性,避免陷入局部最优解或过拟合问题。
自适应学习率算法的基本原理
自适应学习率算法的核心思想是通过历史梯度信息或其他统计量来动态调整学习率。例如,某些算法会根据梯度的大小或方向来调整学习率,以确保在训练初期使用较大的学习率快速收敛,而在接近最优解时使用较小的学习率以提高精度。这种方法通常结合了动量方法和自适应方法的优点,能够更灵活地应对复杂的优化问题。
常见的自适应学习率算法
- AdaGrad
AdaGrad 是一种基于梯度平方和累积的自适应学习率算法。它通过累积梯度的平方和来调整每个参数的学习率,使得频繁出现梯度较大的参数具有较小的学习率,而梯度较小的参数则具有较大的学习率。这种方法适用于稀疏数据和非平稳目标函数 - RMSProp
RMSProp 是另一种基于指数加权移动平均的自适应学习率算法。它通过计算梯度的指数加权平均值来调整学习率,从而避免了 AdaGrad 中累积平方和可能导致的学习率过早减小的问题。RMSProp 的变体包括 RAdam 和 NAdam,它们进一步优化了学习率的调整方式。 - Adam
Adam 是目前最常用的自适应学习率算法之一,结合了 AdaGrad 和 RMSProp 的优点。它通过计算梯度的一阶矩估计(动量)和二阶矩估计(中心化方差)来调整学习率。Adam 算法在实践中表现出色,尤其适用于大规模深度学习模型。 - AdaDelta
AdaDelta 是一种基于梯度平方的指数加权移动平均的自适应学习率算法。它通过计算梯度平方的指数加权平均值来调整学习率,避免了 AdaGrad 中累积平方和可能导致的学习率过早减小的问题。 - Nesterov Accelerated Gradient (NAG)
NAG 是一种带有动量的优化算法,通过在更新参数之前先预测梯度的方向来加速收敛。它结合了动量方法和自适应学习率的优点,能够更有效地处理非凸优化问题。 - vSGD
vSGD 是一种基于变分梯度下降的自适应学习率算法,通过调整参数梯度方差和对角线海森矩阵估计来优化学习率。它在神经网络训练中表现出较好的性能。
自适应学习率算法的应用
自适应学习率算法广泛应用于深度学习、强化学习和其他优化问题中。例如,在深度神经网络训练中,Adam 和 RMSProp 等算法被证明能够显著提高训练速度和模型性能。 在强化学习中,自适应学习率也被用于加速算法收敛并提升性能。
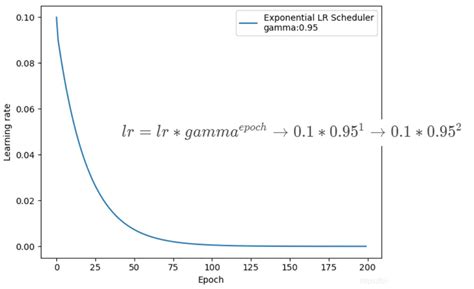
Pytorch深度学习—学习率调整策略_自适应学习率调节
总结
自适应学习率算法通过动态调整学习率来优化模型训练过程,能够显著提高收敛速度和模型性能。常见的自适应学习率算法包括 AdaGrad、RMSProp、Adam、AdaDelta 和 NAG 等。这些算法在深度学习和优化问题中得到了广泛应用,并且在实践中表现出色。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!