潜在语义分析(Latent Semantic Analysis,简称LSA)是一种用于自然语言处理和信息检索的计算和统计方法。其核心思想是通过分析大量文本数据中的词语共现模式,揭示词语和文档之间的隐含语义结构。LSA的基本假设是,如果两个词语在多个文档中频繁共现,则它们在语义上具有相似性。
LSA的工作原理
- 构建词-文档矩阵:
- 奇异值分解(SVD):
- 使用奇异值分解技术对词-文档矩阵进行降维处理。SVD将矩阵分解为三个矩阵:U、Σ 和
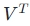 ,其中 U 和 是正交矩阵,Σ 是对角矩阵,包含奇异值。
,其中 U 和 是正交矩阵,Σ 是对角矩阵,包含奇异值。 - 通过选择前 k 个最大的奇异值,可以将词-文档矩阵近似为
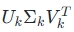 ,从而降低矩阵的维度并去除噪声。
,从而降低矩阵的维度并去除噪声。
- 使用奇异值分解技术对词-文档矩阵进行降维处理。SVD将矩阵分解为三个矩阵:U、Σ 和
- 提取语义信息:
- 降维后的矩阵 将词语和文档映射到一个低维的语义空间中。在这个空间中,词语和文档的向量表示反映了它们之间的语义关系。
- 通过计算词语向量之间的余弦相似度,可以评估词语之间的语义相似性;通过计算文档向量之间的余弦相似度,可以评估文档之间的相似性。
- 降维后的矩阵
LSA的应用
- 信息检索:
- LSA通过构建词语和文档的语义向量,提高了信息检索的准确性。它能够解决传统向量空间模型中的一词多义和同义词问题,从而提高查全率和查准率。
- 文本分类和聚类:
- LSA可以用于文本分类和聚类任务。通过分析词语和文档的语义向量,可以将相似的文档归为一类,或者将具有相似主题的文档聚类在一起。
- 主题建模:
- LSA可以用于主题建模,通过分析文档中词语的分布,提取出文档的主题或概念。
- 自然语言处理:
- LSA在自然语言处理的多个领域中都有应用,包括机器翻译、文本摘要、情感分析等。
LSA的优点和局限性
优点:
- LSA能够捕捉词语和文档之间的隐含语义关系,提高信息检索和文本分析的准确性。
- 它是一种无监督学习方法,不需要外部知识或训练数据。
局限性:
- LSA假设词语的语义是静态的,忽略了上下文的变化。
- 它无法处理多义词和歧义性问题。
- 计算复杂度较高,尤其是在处理大规模文本数据时。
实现方法
在Python中实现LSA通常包括以下步骤:
- 预处理文本数据:分词、去除停用词、计算TF-IDF值。
- 构建词-文档矩阵:使用TF-IDF值填充矩阵。
- 奇异值分解:使用NumPy或SciPy库进行SVD。
- 降维和语义分析:选择前 k个奇异值进行降维,并计算词语和文档的语义向量。
潜在语义分析(LSA)是一种强大的文本分析工具,通过揭示文本数据中的隐含语义结构,为自然语言处理和信息检索等领域提供了重要的技术支持。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!