混合精度训练(Mixed Precision Training,简称MPT)是一种在深度学习模型训练过程中通过结合使用不同精度的数据类型(如FP32和FP16)来提高计算效率、减少内存占用并加速训练的技术。这种技术的核心思想是在模型的不同部分采用不同的数值精度,从而在保持模型准确性的同时优化资源消耗。
混合精度训练的基本原理
混合精度训练通过动态分配模型组件的精度,利用低精度(如FP16)进行计算密集型操作(如卷积和矩阵乘法),而保留高精度(如FP32)用于需要更高精度的步骤(如梯度更新和损失函数计算)。这种方法可以显著减少内存占用和计算时间,同时保持与全精度训练相近的模型性能。
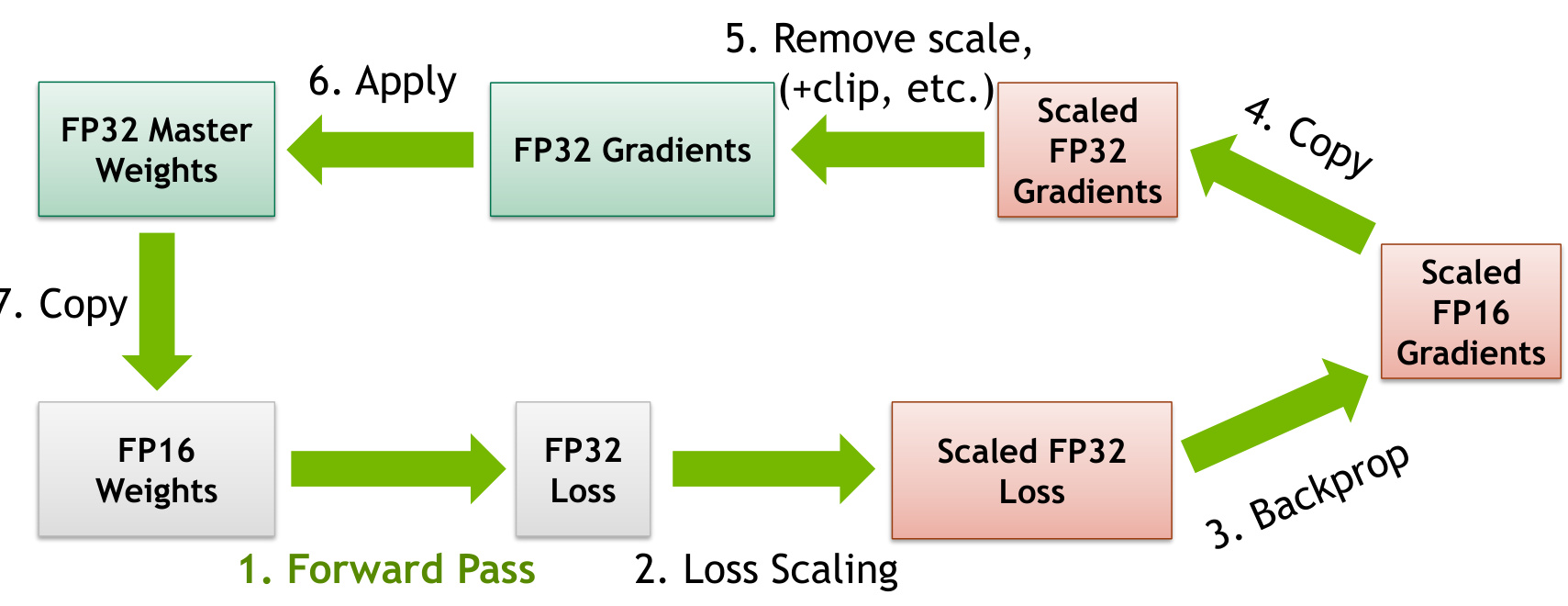
具体来说,混合精度训练通常包括以下步骤:
- 前向传播:使用较低精度(如FP16)进行计算,以提高计算效率。
- 损失缩放:将损失函数从低精度缩放到高精度(如FP32),以确保梯度更新的准确性。
- 反向传播:使用高精度进行梯度计算,以避免低精度带来的数值不稳定问题。
- 梯度复制:将低精度的梯度复制到高精度,以便在更新权重时保持一致性。
浮点表示与混合精度
混合精度训练的优势
- 加速训练:通过减少内存占用和提高计算效率,混合精度训练可以显著加快模型的训练速度。例如,在某些情况下,混合精度训练可以实现2-4倍的加速效果。
- 节省内存:低精度计算减少了显存需求,使得研究人员能够训练更大规模的模型或处理更大的数据集。
- 硬件支持:现代GPU(如NVIDIA的Volta、Turing和Ampere架构)提供了专门的硬件支持(如Tensor Cores),进一步提升了混合精度训练的效率。
- 灵活性:混合精度训练可以根据具体需求灵活调整精度分配,例如在某些层或操作中使用更高精度以确保稳定性。

Pytorch混合精度(FP16&FP32)(AMP自动混合精度)/半精度 训练(一)
混合精度训练的挑战与解决方案
尽管混合精度训练具有显著优势,但在实际应用中也面临一些挑战:
- 数值稳定性:低精度计算可能导致梯度消失或爆炸等问题。为了解决这一问题,通常会采用动态损失缩放(Dynamic Loss Scaling)和混合精度优化器(Mixed Precision Optimizer)等技术。
- 权重更新问题:由于低精度计算可能导致权重更新不准确,因此需要在反向传播过程中将低精度梯度复制到高精度以确保权重更新的一致性。
- 工具支持:许多深度学习框架(如TensorFlow、PyTorch和MindSpore)提供了自动化的混合精度训练工具(如AMP),简化了配置和实现过程。
混合精度训练的应用场景
混合精度训练广泛应用于各种深度学习任务中,包括计算机视觉、自然语言处理和大规模语言模型训练等。例如,在大规模语言模型中,混合精度训练不仅能够显著减少内存占用,还能提升模型的泛化能力。
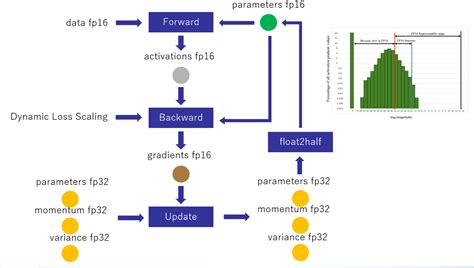
混合精度训练的细节
总结
混合精度训练是一种高效且实用的技术,通过结合不同精度的数据类型,在保证模型准确性的同时优化计算资源。它已经在许多主流深度学习框架中得到广泛应用,并成为加速深度学习模型训练的重要手段之一。未来,随着硬件技术的进步和算法优化的深入,混合精度训练有望在更多领域发挥更大的作用
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!