模型压缩技术是一种旨在减少机器学习模型大小、降低计算复杂度和存储需求的技术,同时尽可能保持模型的预测性能。这种技术广泛应用于资源受限的设备(如移动设备、嵌入式设备和边缘计算设备)以及需要高效推理的场景中,例如自动驾驶、医疗诊断和实时语音识别等。
模型压缩技术的主要方法
根据现有资料,模型压缩技术可以分为以下几类:
- 参数剪枝(Pruning)
参数剪枝通过移除神经网络中不重要的权重或神经元来减小模型大小。具体方法包括: - 量化(Quantization)
量化是将浮点数权重或激活值转换为低比特宽度整数的过程,从而减少存储空间和计算复杂度。量化技术分为:- 静态量化:在推理前固定剪裁范围。
- 动态量化:在推理时动态调整剪裁范围。
此外,还有权重量化(Weight-Only Quantization)、权重激活量化(Weight-Aware Quantization)等。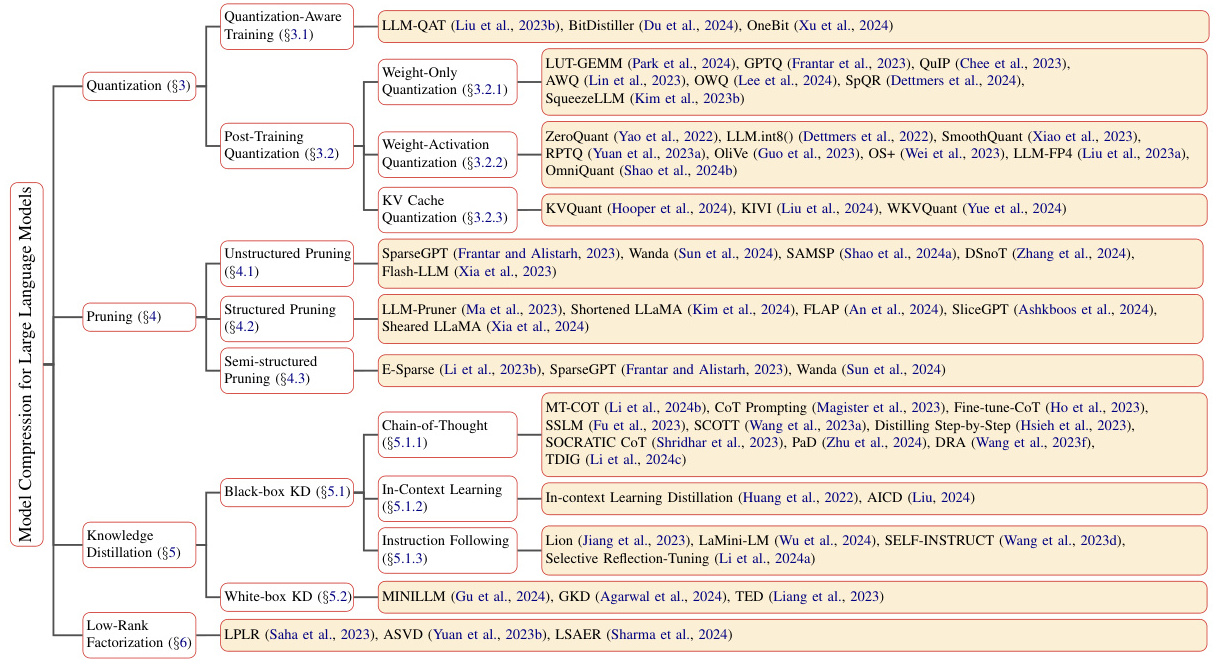

- 知识蒸馏(Knowledge Distillation)
知识蒸馏通过训练小型模型模仿大型模型的行为,将复杂模型的知识传递给轻量级模型。其主要方法包括: - 低秩分解(Low-Rank Decomposition)
低秩分解通过将权重矩阵分解为多个低秩矩阵来减少参数数量。常用的方法包括: - 紧凑网络设计(Compact Network Design)
紧凑网络设计通过优化网络架构来减少模型大小,例如MobileNet、EfficientNet和SqueezeNet等。 - 其他方法
包括稀疏化加速训练、模型蒸馏、长序列压缩等。
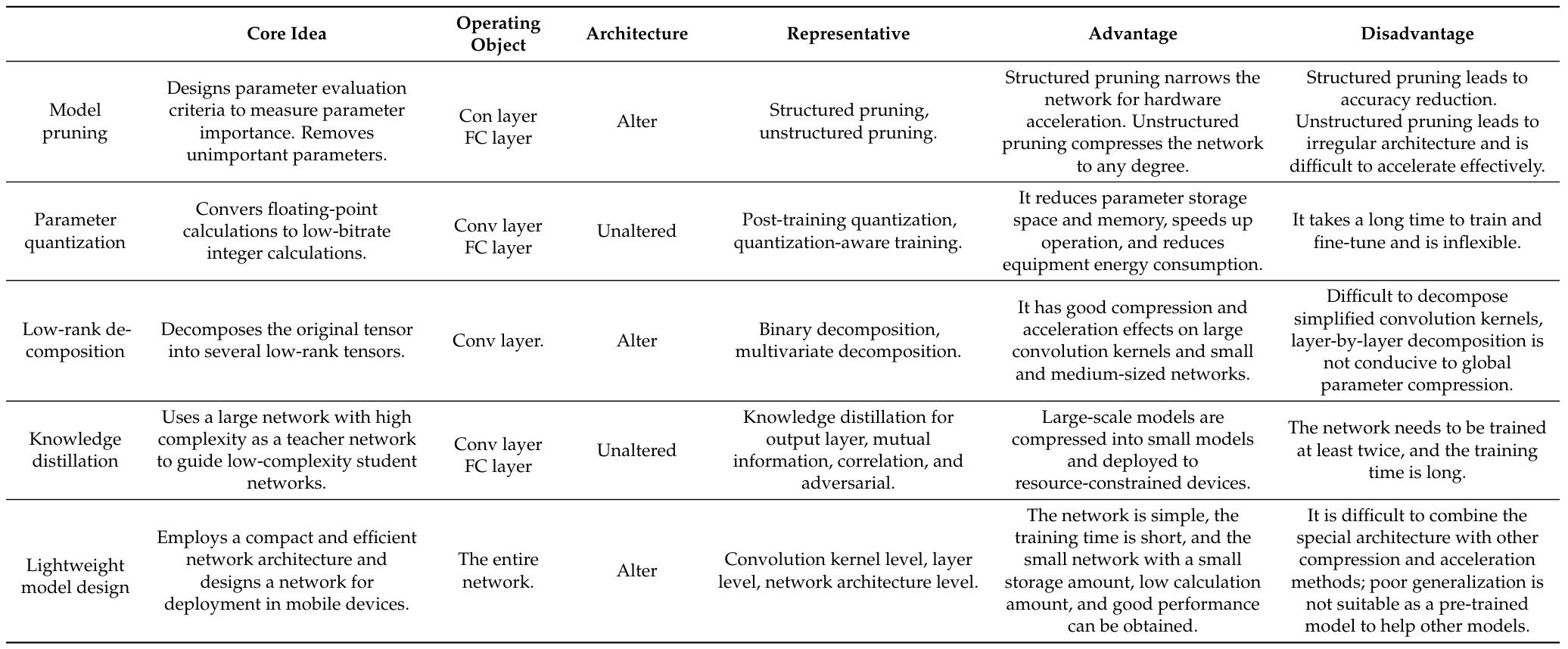
应用场景
模型压缩技术在多个领域展现了显著的应用潜力:
挑战与未来发展方向
尽管模型压缩技术取得了显著进展,但仍面临一些挑战:
- 性能损失:过度压缩可能导致模型精度下降。
- 硬件兼容性:不同硬件平台对压缩算法的支持程度不同。
- 自动化工具:开发更高效的自动化工具以简化压缩过程。
未来的发展方向包括:
- 开发更高效的压缩算法,提高压缩率和模型精度。
- 将模型压缩技术应用于更多实际场景,如自动驾驶和医疗诊断。
- 探索多模态融合环境下的压缩方法。
综上,模型压缩技术通过多种方法优化模型大小和计算效率,广泛应用于资源受限的场景中,并在学术研究和工业界均取得了重要进展。然而,如何平衡压缩率与性能损失仍是未来研究的重要课题
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!