微平均(Micro-averaging)是一种用于多分类问题性能评估的指标计算方法,其核心思想是将所有类别的预测结果汇总到一个全局混淆矩阵中,然后基于该矩阵计算整体的性能指标。这种方法特别适用于类别不平衡的情况,因为它不会因为某些类别的样本数量较少而被忽视。
微平均的定义与计算公式
微平均通过对所有类别的真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)进行汇总,建立一个全局混淆矩阵,然后基于该矩阵计算整体的精确率、召回率和F1分数等指标。具体公式如下:
计算公式.jpg)
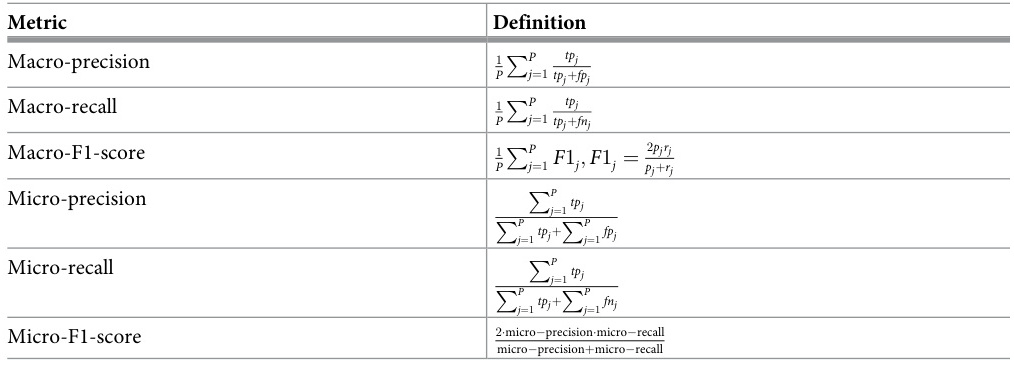
微平均的特点
- 对高频类别的敏感性:由于微平均将所有类别的预测结果汇总到一个全局混淆矩阵中,因此它会放大高频类别的影响。这意味着如果某些类别的样本数量远多于其他类别,这些类别的性能将对整体评估结果产生更大的影响。
- 适用于类别不平衡场景:在类别不平衡的情况下,微平均能够更好地反映模型的整体性能,因为它不会因为少数类别的低样本量而被忽略。
- 与准确率的区别:微平均的结果通常与准确率不同。准确率是所有正确预测的样本数占总样本数的比例,而微平均则是基于全局混淆矩阵计算的整体性能指标。在类别不平衡的情况下,微平均可能比准确率更能反映模型的真实性能。
微平均的应用场景
微平均广泛应用于多分类问题的性能评估,尤其是在以下场景中:
- 类别不平衡:当某些类别的样本数量远多于其他类别时,微平均能够更好地反映模型的整体性能。
- 需要全局性能评估:在需要综合考虑所有类别性能的情况下,微平均提供了一个全局的性能指标。
微平均与宏平均(Macro-averaging)的对比
宏平均(Macro-averaging)是另一种常用的多分类性能评估方法,其特点是将每个类别的性能指标(如精确率、召回率和F1分数)分别计算出来后取平均值。宏平均的优点是能够公平对待所有类别,但缺点是它忽略了高频类别的影响。
相比之下,微平均更加关注高频类别的性能,因此在类别不平衡的情况下可能更可靠。然而,这也意味着它可能会放大高频类别的影响,从而掩盖低频类别的性能问题。
总结
微平均是一种基于全局混淆矩阵计算的多分类性能评估方法,适用于类别不平衡的场景。它通过汇总所有类别的预测结果来计算整体性能指标,能够更好地反映高频类别的影响。然而,在某些情况下,它可能会放大高频类别的贡献,因此需要根据具体应用场景选择合适的评估方法
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!